Model Training¶
This tutorial demonstrates the training of the TemporalFusionTransformer model.
The demonstration is using the processed version of Corporación Favorita Grocery Sales Forecasting dataset, as demonstrated in the Favorita Dataset Creation Example tutorial, which is also part of this documentation.
The training routine implemented below, uses pure pytorch, for clarity purposes. However, it can be easily adapted to frameworks such as pytorch-ignite or pytorch-lightning to facilitate, orchestrate, and automate some of the training procedure.
For a comprehensive explanation of the model and its structure, refer to our blogpost.
Importing the required libraries¶
[4]:
%load_ext autoreload
%autoreload 2
[5]:
import pickle
from typing import Dict,List,Tuple
from functools import partial
import copy
import numpy as np
from omegaconf import OmegaConf,DictConfig
import pandas as pd
from tqdm import tqdm
import torch
from torch import optim
from torch import nn
import torch.nn.init as init
from torch.utils.data import Dataset, DataLoader, Subset
from tft_torch.tft import TemporalFusionTransformer
import tft_torch.loss as tft_loss
Training Settings¶
Let’s go over to required parameters which will control the training routine:
[24]:
# If early stopping is not triggered, after how many epochs should we quit training
max_epochs = 10000
# how many training batches will compose a single training epoch
epoch_iters = 200
# upon completing a training epoch, we perform an evaluation of all the subsets
# eval_iters will define how many batches of each set will compose a single evaluation round
eval_iters = 500
# during training, on what frequency should we display the monitored performance
log_interval = 20
# what is the running-window used by our QueueAggregator object for monitoring the training performance
ma_queue_size = 50
# how many evaluation rounds should we allow,
# without any improvement in the performance observed on the validation set
patience = 5
[25]:
# initialize early stopping mechanism
es = EarlyStopping(patience=patience)
# initialize the loss aggregator for running window performance estimation
loss_aggregator = QueueAggregator(max_size=ma_queue_size)
# initialize counters
batch_idx = 0
epoch_idx = 0
For computing the loss we are seeking to optimize, we need to define a tensor, corresponding to the actual quantiles we want to estimate:
[26]:
quantiles_tensor = torch.tensor(configuration['model']['output_quantiles']).to(device)
The following cell implements the way each batch is processed by our training/evaluation procedure. We transfer each batch component to the device we’re using, feed the batch to the model, and compute the loss, using the labels (which are part of our batch), the predicted_quantiles output, and the fixed tensor quantiles_tensor stating the quantiles we wish to estimate.
[27]:
def process_batch(batch: Dict[str,torch.tensor],
model: nn.Module,
quantiles_tensor: torch.tensor,
device:torch.device):
if is_cuda:
for k in list(batch.keys()):
batch[k] = batch[k].to(device)
batch_outputs = model(batch)
labels = batch['target']
predicted_quantiles = batch_outputs['predicted_quantiles']
q_loss, q_risk, _ = tft_loss.get_quantiles_loss_and_q_risk(outputs=predicted_quantiles,
targets=labels,
desired_quantiles=quantiles_tensor)
return q_loss, q_risk
Now, finally, is the actual training loop. This loop will go on until completing max_epoch rounds, or until EarlyStopping is triggered.
Each epoch starts with the evaluation of each of the subsets. Each evaluation rounds includes the processing of eval_iters batches from the relevant subset, after which the losses and the metrics are concatenated and averaged. The loss computed for the validation set is fed to the early stopping mechanism for continuous tracking.
After completing the evaluation of the data subsets, a training round, including the processing of epoch_iters batches from the training subset, is initiated. For each training batch, the computed loss is used for calling the optimizer to update the model weights, and added to the loss aggregator.
[28]:
while epoch_idx < max_epochs:
print(f"Starting Epoch Index {epoch_idx}")
# evaluation round
model.eval()
with torch.no_grad():
# for each subset
for subset_name, subset_loader in zip(['train','validation','test'],[train_loader,validation_loader,test_loader]):
print(f"Evaluating {subset_name} set")
q_loss_vals, q_risk_vals = [],[] # used for aggregating performance along the evaluation round
for _ in range(eval_iters):
# get batch
batch = next(subset_loader)
# process batch
batch_loss,batch_q_risk = process_batch(batch=batch,model=model,quantiles_tensor=quantiles_tensor,device=device)
# accumulate performance
q_loss_vals.append(batch_loss)
q_risk_vals.append(batch_q_risk)
# aggregate and average
eval_loss = torch.stack(q_loss_vals).mean(axis=0)
eval_q_risk = torch.stack(q_risk_vals,axis=0).mean(axis=0)
# keep for feeding the early stopping mechanism
if subset_name == 'validation':
validation_loss = eval_loss
# log performance
print(f"Epoch: {epoch_idx}, Batch Index: {batch_idx}" + \
f"- Eval {subset_name} - " + \
f"q_loss = {eval_loss:.5f} , " + \
" , ".join([f"q_risk_{q:.1} = {risk:.5f}" for q,risk in zip(quantiles_tensor,eval_q_risk)]))
# switch to training mode
model.train()
# update early stopping mechanism and stop if triggered
if es.step(validation_loss):
print('Performing early stopping...!')
break
# initiating a training round
for _ in range(epoch_iters):
# get training batch
batch = next(train_loader)
opt.zero_grad()
# process batch
loss,_ = process_batch(batch=batch,
model=model,
quantiles_tensor=quantiles_tensor,
device=device)
# compute gradients
loss.backward()
# gradient clipping
if configuration['optimization']['max_grad_norm'] > 0:
nn.utils.clip_grad_norm_(model.parameters(), configuration['optimization']['max_grad_norm'])
# update weights
opt.step()
# accumulate performance
loss_aggregator.append(loss.item())
# log performance
if batch_idx % log_interval == 0:
print(f"Epoch: {epoch_idx}, Batch Index: {batch_idx} - Train Loss = {np.mean(loss_aggregator.get())}")
# completed batch
batch_idx += 1
# completed epoch
epoch_idx += 1
Starting Epoch Index 0
Evaluating train set
Epoch: 0, Batch Index: 0- Eval train - q_loss = 2.03305 , q_risk_0.1 = 2.15217 , q_risk_0.5 = 1.50869 , q_risk_0.9 = 1.42569
Evaluating validation set
Epoch: 0, Batch Index: 0- Eval validation - q_loss = 2.09707 , q_risk_0.1 = 2.79929 , q_risk_0.5 = 1.31844 , q_risk_0.9 = 1.11522
Evaluating test set
Epoch: 0, Batch Index: 0- Eval test - q_loss = 1.98208 , q_risk_0.1 = 2.24149 , q_risk_0.5 = 1.40397 , q_risk_0.9 = 1.35933
Epoch: 0, Batch Index: 0 - Train Loss = 2.020455837249756
Epoch: 0, Batch Index: 20 - Train Loss = 0.7724506230581374
Epoch: 0, Batch Index: 40 - Train Loss = 0.6347503349548433
Epoch: 0, Batch Index: 60 - Train Loss = 0.5004462844133377
Epoch: 0, Batch Index: 80 - Train Loss = 0.44857171654701233
Epoch: 0, Batch Index: 100 - Train Loss = 0.43766250789165495
Epoch: 0, Batch Index: 120 - Train Loss = 0.43416002750396726
Epoch: 0, Batch Index: 140 - Train Loss = 0.4331358313560486
Epoch: 0, Batch Index: 160 - Train Loss = 0.43066891729831697
Epoch: 0, Batch Index: 180 - Train Loss = 0.42729145765304566
Starting Epoch Index 1
Evaluating train set
Epoch: 1, Batch Index: 200- Eval train - q_loss = 0.42002 , q_risk_0.1 = 0.23620 , q_risk_0.5 = 0.56292 , q_risk_0.9 = 0.25254
Evaluating validation set
Epoch: 1, Batch Index: 200- Eval validation - q_loss = 0.39472 , q_risk_0.1 = 0.20502 , q_risk_0.5 = 0.53681 , q_risk_0.9 = 0.24385
Evaluating test set
Epoch: 1, Batch Index: 200- Eval test - q_loss = 0.43020 , q_risk_0.1 = 0.23920 , q_risk_0.5 = 0.58177 , q_risk_0.9 = 0.26610
Epoch: 1, Batch Index: 200 - Train Loss = 0.42498995423316954
Epoch: 1, Batch Index: 220 - Train Loss = 0.42323225796222685
Epoch: 1, Batch Index: 240 - Train Loss = 0.4226619130373001
Epoch: 1, Batch Index: 260 - Train Loss = 0.4221925890445709
Epoch: 1, Batch Index: 280 - Train Loss = 0.42066602885723114
Epoch: 1, Batch Index: 300 - Train Loss = 0.41808026492595673
Epoch: 1, Batch Index: 320 - Train Loss = 0.4159805303812027
Epoch: 1, Batch Index: 340 - Train Loss = 0.4174565130472183
Epoch: 1, Batch Index: 360 - Train Loss = 0.4196115469932556
Epoch: 1, Batch Index: 380 - Train Loss = 0.42100709676742554
Starting Epoch Index 2
Evaluating train set
Epoch: 2, Batch Index: 400- Eval train - q_loss = 0.41395 , q_risk_0.1 = 0.23116 , q_risk_0.5 = 0.55721 , q_risk_0.9 = 0.24765
Evaluating validation set
Epoch: 2, Batch Index: 400- Eval validation - q_loss = 0.38804 , q_risk_0.1 = 0.20017 , q_risk_0.5 = 0.52711 , q_risk_0.9 = 0.24130
Evaluating test set
Epoch: 2, Batch Index: 400- Eval test - q_loss = 0.42346 , q_risk_0.1 = 0.23246 , q_risk_0.5 = 0.57313 , q_risk_0.9 = 0.26003
Epoch: 2, Batch Index: 400 - Train Loss = 0.4180942130088806
Epoch: 2, Batch Index: 420 - Train Loss = 0.41510038435459135
Epoch: 2, Batch Index: 440 - Train Loss = 0.41567377269268035
Epoch: 2, Batch Index: 460 - Train Loss = 0.41648059606552124
Epoch: 2, Batch Index: 480 - Train Loss = 0.41558587193489077
Epoch: 2, Batch Index: 500 - Train Loss = 0.4143910664319992
Epoch: 2, Batch Index: 520 - Train Loss = 0.41360773086547853
Epoch: 2, Batch Index: 540 - Train Loss = 0.4148547148704529
Epoch: 2, Batch Index: 560 - Train Loss = 0.41554462850093843
Epoch: 2, Batch Index: 580 - Train Loss = 0.4137012666463852
Starting Epoch Index 3
Evaluating train set
Epoch: 3, Batch Index: 600- Eval train - q_loss = 0.40949 , q_risk_0.1 = 0.22791 , q_risk_0.5 = 0.55206 , q_risk_0.9 = 0.24633
Evaluating validation set
Epoch: 3, Batch Index: 600- Eval validation - q_loss = 0.38416 , q_risk_0.1 = 0.19762 , q_risk_0.5 = 0.52276 , q_risk_0.9 = 0.23902
Evaluating test set
Epoch: 3, Batch Index: 600- Eval test - q_loss = 0.41854 , q_risk_0.1 = 0.23092 , q_risk_0.5 = 0.56851 , q_risk_0.9 = 0.25763
Epoch: 3, Batch Index: 600 - Train Loss = 0.41306958615779876
Epoch: 3, Batch Index: 620 - Train Loss = 0.41319740533828736
Epoch: 3, Batch Index: 640 - Train Loss = 0.41450446128845214
Epoch: 3, Batch Index: 660 - Train Loss = 0.4108119714260101
Epoch: 3, Batch Index: 680 - Train Loss = 0.40992509841918945
Epoch: 3, Batch Index: 700 - Train Loss = 0.4079200464487076
Epoch: 3, Batch Index: 720 - Train Loss = 0.409369660615921
Epoch: 3, Batch Index: 740 - Train Loss = 0.4104118537902832
Epoch: 3, Batch Index: 760 - Train Loss = 0.4100472277402878
Epoch: 3, Batch Index: 780 - Train Loss = 0.4100530457496643
Starting Epoch Index 4
Evaluating train set
Epoch: 4, Batch Index: 800- Eval train - q_loss = 0.40630 , q_risk_0.1 = 0.22670 , q_risk_0.5 = 0.54644 , q_risk_0.9 = 0.24413
Evaluating validation set
Epoch: 4, Batch Index: 800- Eval validation - q_loss = 0.38275 , q_risk_0.1 = 0.19644 , q_risk_0.5 = 0.51953 , q_risk_0.9 = 0.24003
Evaluating test set
Epoch: 4, Batch Index: 800- Eval test - q_loss = 0.41674 , q_risk_0.1 = 0.22941 , q_risk_0.5 = 0.56476 , q_risk_0.9 = 0.25801
Epoch: 4, Batch Index: 800 - Train Loss = 0.40925871193408964
Epoch: 4, Batch Index: 820 - Train Loss = 0.4090828377008438
Epoch: 4, Batch Index: 840 - Train Loss = 0.4069894003868103
Epoch: 4, Batch Index: 860 - Train Loss = 0.40759585201740267
Epoch: 4, Batch Index: 880 - Train Loss = 0.4058069509267807
Epoch: 4, Batch Index: 900 - Train Loss = 0.40712576448917387
Epoch: 4, Batch Index: 920 - Train Loss = 0.40775597989559176
Epoch: 4, Batch Index: 940 - Train Loss = 0.4076818293333054
Epoch: 4, Batch Index: 960 - Train Loss = 0.40606608867645266
Epoch: 4, Batch Index: 980 - Train Loss = 0.4045009380578995
Starting Epoch Index 5
Evaluating train set
Epoch: 5, Batch Index: 1000- Eval train - q_loss = 0.40445 , q_risk_0.1 = 0.22491 , q_risk_0.5 = 0.54649 , q_risk_0.9 = 0.24098
Evaluating validation set
Epoch: 5, Batch Index: 1000- Eval validation - q_loss = 0.38038 , q_risk_0.1 = 0.19408 , q_risk_0.5 = 0.51852 , q_risk_0.9 = 0.23671
Evaluating test set
Epoch: 5, Batch Index: 1000- Eval test - q_loss = 0.41440 , q_risk_0.1 = 0.22713 , q_risk_0.5 = 0.56470 , q_risk_0.9 = 0.25405
Epoch: 5, Batch Index: 1000 - Train Loss = 0.4067613816261291
Epoch: 5, Batch Index: 1020 - Train Loss = 0.4067066353559494
Epoch: 5, Batch Index: 1040 - Train Loss = 0.40532047510147096
Epoch: 5, Batch Index: 1060 - Train Loss = 0.4045089113712311
Epoch: 5, Batch Index: 1080 - Train Loss = 0.4038675820827484
Epoch: 5, Batch Index: 1100 - Train Loss = 0.4051359671354294
Epoch: 5, Batch Index: 1120 - Train Loss = 0.40533805549144747
Epoch: 5, Batch Index: 1140 - Train Loss = 0.4062341320514679
Epoch: 5, Batch Index: 1160 - Train Loss = 0.40499836564064023
Epoch: 5, Batch Index: 1180 - Train Loss = 0.4051413434743881
Starting Epoch Index 6
Evaluating train set
Epoch: 6, Batch Index: 1200- Eval train - q_loss = 0.40266 , q_risk_0.1 = 0.22359 , q_risk_0.5 = 0.54319 , q_risk_0.9 = 0.23855
Evaluating validation set
Epoch: 6, Batch Index: 1200- Eval validation - q_loss = 0.38021 , q_risk_0.1 = 0.19417 , q_risk_0.5 = 0.51992 , q_risk_0.9 = 0.23482
Evaluating test set
Epoch: 6, Batch Index: 1200- Eval test - q_loss = 0.41308 , q_risk_0.1 = 0.22795 , q_risk_0.5 = 0.56358 , q_risk_0.9 = 0.25170
Epoch: 6, Batch Index: 1200 - Train Loss = 0.40418831825256346
Epoch: 6, Batch Index: 1220 - Train Loss = 0.40468450009822843
Epoch: 6, Batch Index: 1240 - Train Loss = 0.4058254724740982
Epoch: 6, Batch Index: 1260 - Train Loss = 0.4060604375600815
Epoch: 6, Batch Index: 1280 - Train Loss = 0.4070625078678131
Epoch: 6, Batch Index: 1300 - Train Loss = 0.40513818204402924
Epoch: 6, Batch Index: 1320 - Train Loss = 0.40423076212406156
Epoch: 6, Batch Index: 1340 - Train Loss = 0.40216550648212435
Epoch: 6, Batch Index: 1360 - Train Loss = 0.4020002579689026
Epoch: 6, Batch Index: 1380 - Train Loss = 0.40282262206077574
Starting Epoch Index 7
Evaluating train set
Epoch: 7, Batch Index: 1400- Eval train - q_loss = 0.39914 , q_risk_0.1 = 0.22295 , q_risk_0.5 = 0.53990 , q_risk_0.9 = 0.23707
Evaluating validation set
Epoch: 7, Batch Index: 1400- Eval validation - q_loss = 0.37719 , q_risk_0.1 = 0.19344 , q_risk_0.5 = 0.51450 , q_risk_0.9 = 0.23325
Evaluating test set
Epoch: 7, Batch Index: 1400- Eval test - q_loss = 0.40899 , q_risk_0.1 = 0.22704 , q_risk_0.5 = 0.55840 , q_risk_0.9 = 0.24897
Epoch: 7, Batch Index: 1400 - Train Loss = 0.402779341340065
Epoch: 7, Batch Index: 1420 - Train Loss = 0.40297271132469176
Epoch: 7, Batch Index: 1440 - Train Loss = 0.4026300513744354
Epoch: 7, Batch Index: 1460 - Train Loss = 0.40316272258758545
Epoch: 7, Batch Index: 1480 - Train Loss = 0.4022568541765213
Epoch: 7, Batch Index: 1500 - Train Loss = 0.4006280392408371
Epoch: 7, Batch Index: 1520 - Train Loss = 0.4012106776237488
Epoch: 7, Batch Index: 1540 - Train Loss = 0.40098224580287933
Epoch: 7, Batch Index: 1560 - Train Loss = 0.4003554481267929
Epoch: 7, Batch Index: 1580 - Train Loss = 0.40120102822780607
Starting Epoch Index 8
Evaluating train set
Epoch: 8, Batch Index: 1600- Eval train - q_loss = 0.39869 , q_risk_0.1 = 0.22295 , q_risk_0.5 = 0.54067 , q_risk_0.9 = 0.23733
Evaluating validation set
Epoch: 8, Batch Index: 1600- Eval validation - q_loss = 0.37542 , q_risk_0.1 = 0.19315 , q_risk_0.5 = 0.51215 , q_risk_0.9 = 0.23249
Evaluating test set
Epoch: 8, Batch Index: 1600- Eval test - q_loss = 0.40910 , q_risk_0.1 = 0.22636 , q_risk_0.5 = 0.55779 , q_risk_0.9 = 0.24879
Epoch: 8, Batch Index: 1600 - Train Loss = 0.4011056447029114
Epoch: 8, Batch Index: 1620 - Train Loss = 0.4003825575113297
Epoch: 8, Batch Index: 1640 - Train Loss = 0.4013179081678391
Epoch: 8, Batch Index: 1660 - Train Loss = 0.4005914378166199
Epoch: 8, Batch Index: 1680 - Train Loss = 0.400411833524704
Epoch: 8, Batch Index: 1700 - Train Loss = 0.39901186048984527
Epoch: 8, Batch Index: 1720 - Train Loss = 0.39950142443180087
Epoch: 8, Batch Index: 1740 - Train Loss = 0.40104600429534915
Epoch: 8, Batch Index: 1760 - Train Loss = 0.4011937004327774
Epoch: 8, Batch Index: 1780 - Train Loss = 0.3990417116880417
Starting Epoch Index 9
Evaluating train set
Epoch: 9, Batch Index: 1800- Eval train - q_loss = 0.39769 , q_risk_0.1 = 0.22267 , q_risk_0.5 = 0.53573 , q_risk_0.9 = 0.23551
Evaluating validation set
Epoch: 9, Batch Index: 1800- Eval validation - q_loss = 0.37497 , q_risk_0.1 = 0.19375 , q_risk_0.5 = 0.51019 , q_risk_0.9 = 0.23209
Evaluating test set
Epoch: 9, Batch Index: 1800- Eval test - q_loss = 0.40726 , q_risk_0.1 = 0.22613 , q_risk_0.5 = 0.55291 , q_risk_0.9 = 0.24664
Epoch: 9, Batch Index: 1800 - Train Loss = 0.3984821850061417
Epoch: 9, Batch Index: 1820 - Train Loss = 0.39621995747089384
Epoch: 9, Batch Index: 1840 - Train Loss = 0.397534641623497
Epoch: 9, Batch Index: 1860 - Train Loss = 0.39747892796993256
Epoch: 9, Batch Index: 1880 - Train Loss = 0.39800208926200864
Epoch: 9, Batch Index: 1900 - Train Loss = 0.3982150912284851
Epoch: 9, Batch Index: 1920 - Train Loss = 0.3992548805475235
Epoch: 9, Batch Index: 1940 - Train Loss = 0.40012820780277253
Epoch: 9, Batch Index: 1960 - Train Loss = 0.3997068899869919
Epoch: 9, Batch Index: 1980 - Train Loss = 0.3998417049646378
Starting Epoch Index 10
Evaluating train set
Epoch: 10, Batch Index: 2000- Eval train - q_loss = 0.39851 , q_risk_0.1 = 0.22142 , q_risk_0.5 = 0.53672 , q_risk_0.9 = 0.23679
Evaluating validation set
Epoch: 10, Batch Index: 2000- Eval validation - q_loss = 0.37541 , q_risk_0.1 = 0.19174 , q_risk_0.5 = 0.50991 , q_risk_0.9 = 0.23376
Evaluating test set
Epoch: 10, Batch Index: 2000- Eval test - q_loss = 0.40849 , q_risk_0.1 = 0.22410 , q_risk_0.5 = 0.55475 , q_risk_0.9 = 0.24999
Epoch: 10, Batch Index: 2000 - Train Loss = 0.3990354412794113
Epoch: 10, Batch Index: 2020 - Train Loss = 0.3999947690963745
Epoch: 10, Batch Index: 2040 - Train Loss = 0.39858454167842866
Epoch: 10, Batch Index: 2060 - Train Loss = 0.3993226552009583
Epoch: 10, Batch Index: 2080 - Train Loss = 0.3973876845836639
Epoch: 10, Batch Index: 2100 - Train Loss = 0.3981896710395813
Epoch: 10, Batch Index: 2120 - Train Loss = 0.3981538939476013
Epoch: 10, Batch Index: 2140 - Train Loss = 0.3983695012331009
Epoch: 10, Batch Index: 2160 - Train Loss = 0.3958142375946045
Epoch: 10, Batch Index: 2180 - Train Loss = 0.3963635700941086
Starting Epoch Index 11
Evaluating train set
Epoch: 11, Batch Index: 2200- Eval train - q_loss = 0.39731 , q_risk_0.1 = 0.22121 , q_risk_0.5 = 0.53701 , q_risk_0.9 = 0.23767
Evaluating validation set
Epoch: 11, Batch Index: 2200- Eval validation - q_loss = 0.37305 , q_risk_0.1 = 0.19094 , q_risk_0.5 = 0.50848 , q_risk_0.9 = 0.23342
Evaluating test set
Epoch: 11, Batch Index: 2200- Eval test - q_loss = 0.40681 , q_risk_0.1 = 0.22408 , q_risk_0.5 = 0.55368 , q_risk_0.9 = 0.24790
Epoch: 11, Batch Index: 2200 - Train Loss = 0.397286531329155
Epoch: 11, Batch Index: 2220 - Train Loss = 0.3975470417737961
Epoch: 11, Batch Index: 2240 - Train Loss = 0.39717461585998537
Epoch: 11, Batch Index: 2260 - Train Loss = 0.3976611328125
Epoch: 11, Batch Index: 2280 - Train Loss = 0.3975683742761612
Epoch: 11, Batch Index: 2300 - Train Loss = 0.39604835510253905
Epoch: 11, Batch Index: 2320 - Train Loss = 0.39686691462993623
Epoch: 11, Batch Index: 2340 - Train Loss = 0.39791470289230346
Epoch: 11, Batch Index: 2360 - Train Loss = 0.3995424944162369
Epoch: 11, Batch Index: 2380 - Train Loss = 0.39787294566631315
Starting Epoch Index 12
Evaluating train set
Epoch: 12, Batch Index: 2400- Eval train - q_loss = 0.39626 , q_risk_0.1 = 0.22156 , q_risk_0.5 = 0.53379 , q_risk_0.9 = 0.23491
Evaluating validation set
Epoch: 12, Batch Index: 2400- Eval validation - q_loss = 0.37278 , q_risk_0.1 = 0.19257 , q_risk_0.5 = 0.50609 , q_risk_0.9 = 0.23203
Evaluating test set
Epoch: 12, Batch Index: 2400- Eval test - q_loss = 0.40521 , q_risk_0.1 = 0.22495 , q_risk_0.5 = 0.55083 , q_risk_0.9 = 0.24609
Epoch: 12, Batch Index: 2400 - Train Loss = 0.39735854625701905
Epoch: 12, Batch Index: 2420 - Train Loss = 0.397556711435318
Epoch: 12, Batch Index: 2440 - Train Loss = 0.39656793415546415
Epoch: 12, Batch Index: 2460 - Train Loss = 0.3968496644496918
Epoch: 12, Batch Index: 2480 - Train Loss = 0.39582385659217834
Epoch: 12, Batch Index: 2500 - Train Loss = 0.39432197391986845
Epoch: 12, Batch Index: 2520 - Train Loss = 0.3937902343273163
Epoch: 12, Batch Index: 2540 - Train Loss = 0.39579939663410185
Epoch: 12, Batch Index: 2560 - Train Loss = 0.39682712018489835
Epoch: 12, Batch Index: 2580 - Train Loss = 0.39822638154029844
Starting Epoch Index 13
Evaluating train set
Epoch: 13, Batch Index: 2600- Eval train - q_loss = 0.39503 , q_risk_0.1 = 0.22192 , q_risk_0.5 = 0.53106 , q_risk_0.9 = 0.23303
Evaluating validation set
Epoch: 13, Batch Index: 2600- Eval validation - q_loss = 0.37233 , q_risk_0.1 = 0.19380 , q_risk_0.5 = 0.50514 , q_risk_0.9 = 0.23063
Evaluating test set
Epoch: 13, Batch Index: 2600- Eval test - q_loss = 0.40487 , q_risk_0.1 = 0.22607 , q_risk_0.5 = 0.54981 , q_risk_0.9 = 0.24570
Epoch: 13, Batch Index: 2600 - Train Loss = 0.3985908716917038
Epoch: 13, Batch Index: 2620 - Train Loss = 0.39708409547805784
Epoch: 13, Batch Index: 2640 - Train Loss = 0.39565754354000093
Epoch: 13, Batch Index: 2660 - Train Loss = 0.39411513566970824
Epoch: 13, Batch Index: 2680 - Train Loss = 0.39422193586826326
Epoch: 13, Batch Index: 2700 - Train Loss = 0.39611084043979644
Epoch: 13, Batch Index: 2720 - Train Loss = 0.3958034712076187
Epoch: 13, Batch Index: 2740 - Train Loss = 0.3957914996147156
Epoch: 13, Batch Index: 2760 - Train Loss = 0.39552177786827086
Epoch: 13, Batch Index: 2780 - Train Loss = 0.3972522002458572
Starting Epoch Index 14
Evaluating train set
Epoch: 14, Batch Index: 2800- Eval train - q_loss = 0.39454 , q_risk_0.1 = 0.22024 , q_risk_0.5 = 0.53524 , q_risk_0.9 = 0.23390
Evaluating validation set
Epoch: 14, Batch Index: 2800- Eval validation - q_loss = 0.37213 , q_risk_0.1 = 0.18976 , q_risk_0.5 = 0.50818 , q_risk_0.9 = 0.23144
Evaluating test set
Epoch: 14, Batch Index: 2800- Eval test - q_loss = 0.40552 , q_risk_0.1 = 0.22388 , q_risk_0.5 = 0.55365 , q_risk_0.9 = 0.24705
Epoch: 14, Batch Index: 2800 - Train Loss = 0.39746993958950044
Epoch: 14, Batch Index: 2820 - Train Loss = 0.3977667087316513
Epoch: 14, Batch Index: 2840 - Train Loss = 0.39638291656970975
Epoch: 14, Batch Index: 2860 - Train Loss = 0.3958066064119339
Epoch: 14, Batch Index: 2880 - Train Loss = 0.39620551466941833
Epoch: 14, Batch Index: 2900 - Train Loss = 0.39700751841068266
Epoch: 14, Batch Index: 2920 - Train Loss = 0.39792332887649534
Epoch: 14, Batch Index: 2940 - Train Loss = 0.3981608068943024
Epoch: 14, Batch Index: 2960 - Train Loss = 0.3968786609172821
Epoch: 14, Batch Index: 2980 - Train Loss = 0.39690771281719206
Starting Epoch Index 15
Evaluating train set
Epoch: 15, Batch Index: 3000- Eval train - q_loss = 0.39590 , q_risk_0.1 = 0.22212 , q_risk_0.5 = 0.53453 , q_risk_0.9 = 0.23504
Evaluating validation set
Epoch: 15, Batch Index: 3000- Eval validation - q_loss = 0.37228 , q_risk_0.1 = 0.19195 , q_risk_0.5 = 0.50551 , q_risk_0.9 = 0.23166
Evaluating test set
Epoch: 15, Batch Index: 3000- Eval test - q_loss = 0.40615 , q_risk_0.1 = 0.22639 , q_risk_0.5 = 0.55196 , q_risk_0.9 = 0.24593
Epoch: 15, Batch Index: 3000 - Train Loss = 0.39571544885635374
Epoch: 15, Batch Index: 3020 - Train Loss = 0.3961531764268875
Epoch: 15, Batch Index: 3040 - Train Loss = 0.39620076477527616
Epoch: 15, Batch Index: 3060 - Train Loss = 0.3955254822969437
Epoch: 15, Batch Index: 3080 - Train Loss = 0.3957783627510071
Epoch: 15, Batch Index: 3100 - Train Loss = 0.39409859240055084
Epoch: 15, Batch Index: 3120 - Train Loss = 0.394546263217926
Epoch: 15, Batch Index: 3140 - Train Loss = 0.3941196483373642
Epoch: 15, Batch Index: 3160 - Train Loss = 0.3953500097990036
Epoch: 15, Batch Index: 3180 - Train Loss = 0.39435318410396575
Starting Epoch Index 16
Evaluating train set
Epoch: 16, Batch Index: 3200- Eval train - q_loss = 0.39311 , q_risk_0.1 = 0.22106 , q_risk_0.5 = 0.53087 , q_risk_0.9 = 0.23375
Evaluating validation set
Epoch: 16, Batch Index: 3200- Eval validation - q_loss = 0.36995 , q_risk_0.1 = 0.19182 , q_risk_0.5 = 0.50196 , q_risk_0.9 = 0.23022
Evaluating test set
Epoch: 16, Batch Index: 3200- Eval test - q_loss = 0.40404 , q_risk_0.1 = 0.22498 , q_risk_0.5 = 0.54958 , q_risk_0.9 = 0.24624
Epoch: 16, Batch Index: 3200 - Train Loss = 0.39327936828136445
Epoch: 16, Batch Index: 3220 - Train Loss = 0.39240858078002927
Epoch: 16, Batch Index: 3240 - Train Loss = 0.39418687641620637
Epoch: 16, Batch Index: 3260 - Train Loss = 0.3960178005695343
Epoch: 16, Batch Index: 3280 - Train Loss = 0.39683654487133024
Epoch: 16, Batch Index: 3300 - Train Loss = 0.3963241118192673
Epoch: 16, Batch Index: 3320 - Train Loss = 0.39427025318145753
Epoch: 16, Batch Index: 3340 - Train Loss = 0.39327972531318667
Epoch: 16, Batch Index: 3360 - Train Loss = 0.39355730831623076
Epoch: 16, Batch Index: 3380 - Train Loss = 0.3935112875699997
Starting Epoch Index 17
Evaluating train set
Epoch: 17, Batch Index: 3400- Eval train - q_loss = 0.39267 , q_risk_0.1 = 0.21894 , q_risk_0.5 = 0.52937 , q_risk_0.9 = 0.23373
Evaluating validation set
Epoch: 17, Batch Index: 3400- Eval validation - q_loss = 0.36965 , q_risk_0.1 = 0.18946 , q_risk_0.5 = 0.50238 , q_risk_0.9 = 0.23064
Evaluating test set
Epoch: 17, Batch Index: 3400- Eval test - q_loss = 0.40385 , q_risk_0.1 = 0.22403 , q_risk_0.5 = 0.55088 , q_risk_0.9 = 0.24741
Epoch: 17, Batch Index: 3400 - Train Loss = 0.3934555548429489
Epoch: 17, Batch Index: 3420 - Train Loss = 0.39430442929267884
Epoch: 17, Batch Index: 3440 - Train Loss = 0.394860475063324
Epoch: 17, Batch Index: 3460 - Train Loss = 0.3947139686346054
Epoch: 17, Batch Index: 3480 - Train Loss = 0.3969425678253174
Epoch: 17, Batch Index: 3500 - Train Loss = 0.39629222512245177
Epoch: 17, Batch Index: 3520 - Train Loss = 0.39453535914421084
Epoch: 17, Batch Index: 3540 - Train Loss = 0.39338121831417083
Epoch: 17, Batch Index: 3560 - Train Loss = 0.39583060920238494
Epoch: 17, Batch Index: 3580 - Train Loss = 0.3953281724452972
Starting Epoch Index 18
Evaluating train set
Epoch: 18, Batch Index: 3600- Eval train - q_loss = 0.39411 , q_risk_0.1 = 0.22071 , q_risk_0.5 = 0.53185 , q_risk_0.9 = 0.23386
Evaluating validation set
Epoch: 18, Batch Index: 3600- Eval validation - q_loss = 0.37043 , q_risk_0.1 = 0.19030 , q_risk_0.5 = 0.50372 , q_risk_0.9 = 0.23137
Evaluating test set
Epoch: 18, Batch Index: 3600- Eval test - q_loss = 0.40424 , q_risk_0.1 = 0.22493 , q_risk_0.5 = 0.54978 , q_risk_0.9 = 0.24472
Epoch: 18, Batch Index: 3600 - Train Loss = 0.3962299686670303
Epoch: 18, Batch Index: 3620 - Train Loss = 0.3964512723684311
Epoch: 18, Batch Index: 3640 - Train Loss = 0.39531580328941346
Epoch: 18, Batch Index: 3660 - Train Loss = 0.3951317095756531
Epoch: 18, Batch Index: 3680 - Train Loss = 0.39483638882637023
Epoch: 18, Batch Index: 3700 - Train Loss = 0.39424086570739747
Epoch: 18, Batch Index: 3720 - Train Loss = 0.3934622985124588
Epoch: 18, Batch Index: 3740 - Train Loss = 0.39204382538795474
Epoch: 18, Batch Index: 3760 - Train Loss = 0.39244626939296723
Epoch: 18, Batch Index: 3780 - Train Loss = 0.39162741959095
Starting Epoch Index 19
Evaluating train set
Epoch: 19, Batch Index: 3800- Eval train - q_loss = 0.39236 , q_risk_0.1 = 0.21986 , q_risk_0.5 = 0.53063 , q_risk_0.9 = 0.23303
Evaluating validation set
Epoch: 19, Batch Index: 3800- Eval validation - q_loss = 0.36917 , q_risk_0.1 = 0.19038 , q_risk_0.5 = 0.50183 , q_risk_0.9 = 0.23023
Evaluating test set
Epoch: 19, Batch Index: 3800- Eval test - q_loss = 0.40360 , q_risk_0.1 = 0.22352 , q_risk_0.5 = 0.54832 , q_risk_0.9 = 0.24480
Epoch: 19, Batch Index: 3800 - Train Loss = 0.39128984570503234
Epoch: 19, Batch Index: 3820 - Train Loss = 0.3910816216468811
Epoch: 19, Batch Index: 3840 - Train Loss = 0.3931230807304382
Epoch: 19, Batch Index: 3860 - Train Loss = 0.39342101812362673
Epoch: 19, Batch Index: 3880 - Train Loss = 0.39307539820671084
Epoch: 19, Batch Index: 3900 - Train Loss = 0.39352298736572267
Epoch: 19, Batch Index: 3920 - Train Loss = 0.39266403555870055
Epoch: 19, Batch Index: 3940 - Train Loss = 0.39387556493282316
Epoch: 19, Batch Index: 3960 - Train Loss = 0.3941167360544205
Epoch: 19, Batch Index: 3980 - Train Loss = 0.3933072590827942
Starting Epoch Index 20
Evaluating train set
Epoch: 20, Batch Index: 4000- Eval train - q_loss = 0.39171 , q_risk_0.1 = 0.21977 , q_risk_0.5 = 0.52934 , q_risk_0.9 = 0.23252
Evaluating validation set
Epoch: 20, Batch Index: 4000- Eval validation - q_loss = 0.36842 , q_risk_0.1 = 0.18975 , q_risk_0.5 = 0.49880 , q_risk_0.9 = 0.22967
Evaluating test set
Epoch: 20, Batch Index: 4000- Eval test - q_loss = 0.40268 , q_risk_0.1 = 0.22340 , q_risk_0.5 = 0.54762 , q_risk_0.9 = 0.24478
Epoch: 20, Batch Index: 4000 - Train Loss = 0.3935540908575058
Epoch: 20, Batch Index: 4020 - Train Loss = 0.3945341455936432
Epoch: 20, Batch Index: 4040 - Train Loss = 0.3948543339967728
Epoch: 20, Batch Index: 4060 - Train Loss = 0.39625866651535036
Epoch: 20, Batch Index: 4080 - Train Loss = 0.3947367179393768
Epoch: 20, Batch Index: 4100 - Train Loss = 0.3921550667285919
Epoch: 20, Batch Index: 4120 - Train Loss = 0.3913376384973526
Epoch: 20, Batch Index: 4140 - Train Loss = 0.3914654874801636
Epoch: 20, Batch Index: 4160 - Train Loss = 0.392972172498703
Epoch: 20, Batch Index: 4180 - Train Loss = 0.3916538977622986
Starting Epoch Index 21
Evaluating train set
Epoch: 21, Batch Index: 4200- Eval train - q_loss = 0.39359 , q_risk_0.1 = 0.21875 , q_risk_0.5 = 0.53450 , q_risk_0.9 = 0.23349
Evaluating validation set
Epoch: 21, Batch Index: 4200- Eval validation - q_loss = 0.36954 , q_risk_0.1 = 0.18822 , q_risk_0.5 = 0.50501 , q_risk_0.9 = 0.23005
Evaluating test set
Epoch: 21, Batch Index: 4200- Eval test - q_loss = 0.40425 , q_risk_0.1 = 0.22260 , q_risk_0.5 = 0.55251 , q_risk_0.9 = 0.24582
Epoch: 21, Batch Index: 4200 - Train Loss = 0.39065551578998564
Epoch: 21, Batch Index: 4220 - Train Loss = 0.3920184302330017
Epoch: 21, Batch Index: 4240 - Train Loss = 0.39294574737548826
Epoch: 21, Batch Index: 4260 - Train Loss = 0.3921638345718384
Epoch: 21, Batch Index: 4280 - Train Loss = 0.39221913754940035
Epoch: 21, Batch Index: 4300 - Train Loss = 0.39228733897209167
Epoch: 21, Batch Index: 4320 - Train Loss = 0.39290284991264346
Epoch: 21, Batch Index: 4340 - Train Loss = 0.39263272523880005
Epoch: 21, Batch Index: 4360 - Train Loss = 0.39253047585487366
Epoch: 21, Batch Index: 4380 - Train Loss = 0.39298843801021577
Starting Epoch Index 22
Evaluating train set
Epoch: 22, Batch Index: 4400- Eval train - q_loss = 0.39157 , q_risk_0.1 = 0.21867 , q_risk_0.5 = 0.53062 , q_risk_0.9 = 0.23265
Evaluating validation set
Epoch: 22, Batch Index: 4400- Eval validation - q_loss = 0.36894 , q_risk_0.1 = 0.18825 , q_risk_0.5 = 0.50249 , q_risk_0.9 = 0.23015
Evaluating test set
Epoch: 22, Batch Index: 4400- Eval test - q_loss = 0.40272 , q_risk_0.1 = 0.22289 , q_risk_0.5 = 0.55017 , q_risk_0.9 = 0.24553
Epoch: 22, Batch Index: 4400 - Train Loss = 0.3928170812129974
Epoch: 22, Batch Index: 4420 - Train Loss = 0.39240060448646547
Epoch: 22, Batch Index: 4440 - Train Loss = 0.39123848140239714
Epoch: 22, Batch Index: 4460 - Train Loss = 0.39128577649593355
Epoch: 22, Batch Index: 4480 - Train Loss = 0.39194220066070556
Epoch: 22, Batch Index: 4500 - Train Loss = 0.3927388870716095
Epoch: 22, Batch Index: 4520 - Train Loss = 0.3947614371776581
Epoch: 22, Batch Index: 4540 - Train Loss = 0.39322260677814486
Epoch: 22, Batch Index: 4560 - Train Loss = 0.3928615152835846
Epoch: 22, Batch Index: 4580 - Train Loss = 0.3923887598514557
Starting Epoch Index 23
Evaluating train set
Epoch: 23, Batch Index: 4600- Eval train - q_loss = 0.39578 , q_risk_0.1 = 0.21877 , q_risk_0.5 = 0.53504 , q_risk_0.9 = 0.23619
Evaluating validation set
Epoch: 23, Batch Index: 4600- Eval validation - q_loss = 0.37264 , q_risk_0.1 = 0.18828 , q_risk_0.5 = 0.50772 , q_risk_0.9 = 0.23416
Evaluating test set
Epoch: 23, Batch Index: 4600- Eval test - q_loss = 0.40778 , q_risk_0.1 = 0.22321 , q_risk_0.5 = 0.55644 , q_risk_0.9 = 0.25071
Epoch: 23, Batch Index: 4600 - Train Loss = 0.3926751935482025
Epoch: 23, Batch Index: 4620 - Train Loss = 0.3935908442735672
Epoch: 23, Batch Index: 4640 - Train Loss = 0.392884778380394
Epoch: 23, Batch Index: 4660 - Train Loss = 0.3941209644079208
Epoch: 23, Batch Index: 4680 - Train Loss = 0.39364977955818176
Epoch: 23, Batch Index: 4700 - Train Loss = 0.39289494812488557
Epoch: 23, Batch Index: 4720 - Train Loss = 0.3917523670196533
Epoch: 23, Batch Index: 4740 - Train Loss = 0.39211202681064605
Epoch: 23, Batch Index: 4760 - Train Loss = 0.3919273245334625
Epoch: 23, Batch Index: 4780 - Train Loss = 0.39112240612506866
Starting Epoch Index 24
Evaluating train set
Epoch: 24, Batch Index: 4800- Eval train - q_loss = 0.39073 , q_risk_0.1 = 0.21867 , q_risk_0.5 = 0.52852 , q_risk_0.9 = 0.23234
Evaluating validation set
Epoch: 24, Batch Index: 4800- Eval validation - q_loss = 0.36755 , q_risk_0.1 = 0.18810 , q_risk_0.5 = 0.49981 , q_risk_0.9 = 0.22989
Evaluating test set
Epoch: 24, Batch Index: 4800- Eval test - q_loss = 0.40219 , q_risk_0.1 = 0.22368 , q_risk_0.5 = 0.54789 , q_risk_0.9 = 0.24424
Epoch: 24, Batch Index: 4800 - Train Loss = 0.39104080975055694
Epoch: 24, Batch Index: 4820 - Train Loss = 0.3915447109937668
Epoch: 24, Batch Index: 4840 - Train Loss = 0.39162757694721223
Epoch: 24, Batch Index: 4860 - Train Loss = 0.391264573931694
Epoch: 24, Batch Index: 4880 - Train Loss = 0.3915964841842651
Epoch: 24, Batch Index: 4900 - Train Loss = 0.392146959900856
Epoch: 24, Batch Index: 4920 - Train Loss = 0.39214262783527376
Epoch: 24, Batch Index: 4940 - Train Loss = 0.3912676954269409
Epoch: 24, Batch Index: 4960 - Train Loss = 0.390901859998703
Epoch: 24, Batch Index: 4980 - Train Loss = 0.3914948982000351
Starting Epoch Index 25
Evaluating train set
Epoch: 25, Batch Index: 5000- Eval train - q_loss = 0.39103 , q_risk_0.1 = 0.21824 , q_risk_0.5 = 0.52878 , q_risk_0.9 = 0.23258
Evaluating validation set
Epoch: 25, Batch Index: 5000- Eval validation - q_loss = 0.36727 , q_risk_0.1 = 0.18754 , q_risk_0.5 = 0.49930 , q_risk_0.9 = 0.22967
Evaluating test set
Epoch: 25, Batch Index: 5000- Eval test - q_loss = 0.40200 , q_risk_0.1 = 0.22221 , q_risk_0.5 = 0.54803 , q_risk_0.9 = 0.24508
Epoch: 25, Batch Index: 5000 - Train Loss = 0.39295695662498475
Epoch: 25, Batch Index: 5020 - Train Loss = 0.3930238527059555
Epoch: 25, Batch Index: 5040 - Train Loss = 0.39276827991008756
Epoch: 25, Batch Index: 5060 - Train Loss = 0.39349680066108705
Epoch: 25, Batch Index: 5080 - Train Loss = 0.39223547756671906
Epoch: 25, Batch Index: 5100 - Train Loss = 0.39093770444393156
Epoch: 25, Batch Index: 5120 - Train Loss = 0.3900302243232727
Epoch: 25, Batch Index: 5140 - Train Loss = 0.3915100681781769
Epoch: 25, Batch Index: 5160 - Train Loss = 0.39345851361751555
Epoch: 25, Batch Index: 5180 - Train Loss = 0.39556327760219573
Starting Epoch Index 26
Evaluating train set
Epoch: 26, Batch Index: 5200- Eval train - q_loss = 0.39117 , q_risk_0.1 = 0.21851 , q_risk_0.5 = 0.52961 , q_risk_0.9 = 0.23249
Evaluating validation set
Epoch: 26, Batch Index: 5200- Eval validation - q_loss = 0.36806 , q_risk_0.1 = 0.18893 , q_risk_0.5 = 0.50076 , q_risk_0.9 = 0.22973
Evaluating test set
Epoch: 26, Batch Index: 5200- Eval test - q_loss = 0.40395 , q_risk_0.1 = 0.22472 , q_risk_0.5 = 0.54988 , q_risk_0.9 = 0.24445
Epoch: 26, Batch Index: 5200 - Train Loss = 0.39528673231601713
Epoch: 26, Batch Index: 5220 - Train Loss = 0.3938353776931763
Epoch: 26, Batch Index: 5240 - Train Loss = 0.3929093545675278
Epoch: 26, Batch Index: 5260 - Train Loss = 0.393796883225441
Epoch: 26, Batch Index: 5280 - Train Loss = 0.3937105721235275
Epoch: 26, Batch Index: 5300 - Train Loss = 0.3911102694272995
Epoch: 26, Batch Index: 5320 - Train Loss = 0.39100204229354857
Epoch: 26, Batch Index: 5340 - Train Loss = 0.3912016826868057
Epoch: 26, Batch Index: 5360 - Train Loss = 0.3917206537723541
Epoch: 26, Batch Index: 5380 - Train Loss = 0.39080328583717344
Starting Epoch Index 27
Evaluating train set
Epoch: 27, Batch Index: 5400- Eval train - q_loss = 0.39265 , q_risk_0.1 = 0.21775 , q_risk_0.5 = 0.53054 , q_risk_0.9 = 0.23295
Evaluating validation set
Epoch: 27, Batch Index: 5400- Eval validation - q_loss = 0.37037 , q_risk_0.1 = 0.18791 , q_risk_0.5 = 0.50539 , q_risk_0.9 = 0.23140
Evaluating test set
Epoch: 27, Batch Index: 5400- Eval test - q_loss = 0.40449 , q_risk_0.1 = 0.22310 , q_risk_0.5 = 0.55233 , q_risk_0.9 = 0.24602
Epoch: 27, Batch Index: 5400 - Train Loss = 0.3907390028238297
Epoch: 27, Batch Index: 5420 - Train Loss = 0.391916623711586
Epoch: 27, Batch Index: 5440 - Train Loss = 0.39387652039527893
Epoch: 27, Batch Index: 5460 - Train Loss = 0.3932059967517853
Epoch: 27, Batch Index: 5480 - Train Loss = 0.39354217767715455
Epoch: 27, Batch Index: 5500 - Train Loss = 0.3938298052549362
Epoch: 27, Batch Index: 5520 - Train Loss = 0.39483376502990725
Epoch: 27, Batch Index: 5540 - Train Loss = 0.39367376029491424
Epoch: 27, Batch Index: 5560 - Train Loss = 0.39227177858352663
Epoch: 27, Batch Index: 5580 - Train Loss = 0.3912710964679718
Starting Epoch Index 28
Evaluating train set
Epoch: 28, Batch Index: 5600- Eval train - q_loss = 0.39010 , q_risk_0.1 = 0.21711 , q_risk_0.5 = 0.52652 , q_risk_0.9 = 0.23247
Evaluating validation set
Epoch: 28, Batch Index: 5600- Eval validation - q_loss = 0.36690 , q_risk_0.1 = 0.18706 , q_risk_0.5 = 0.49793 , q_risk_0.9 = 0.22968
Evaluating test set
Epoch: 28, Batch Index: 5600- Eval test - q_loss = 0.40209 , q_risk_0.1 = 0.22186 , q_risk_0.5 = 0.54638 , q_risk_0.9 = 0.24374
Epoch: 28, Batch Index: 5600 - Train Loss = 0.39116894245147704
Epoch: 28, Batch Index: 5620 - Train Loss = 0.39049896657466887
Epoch: 28, Batch Index: 5640 - Train Loss = 0.39136357307434083
Epoch: 28, Batch Index: 5660 - Train Loss = 0.3927433145046234
Epoch: 28, Batch Index: 5680 - Train Loss = 0.3914398127794266
Epoch: 28, Batch Index: 5700 - Train Loss = 0.3910479825735092
Epoch: 28, Batch Index: 5720 - Train Loss = 0.39200413167476655
Epoch: 28, Batch Index: 5740 - Train Loss = 0.3924363601207733
Epoch: 28, Batch Index: 5760 - Train Loss = 0.3915549123287201
Epoch: 28, Batch Index: 5780 - Train Loss = 0.3906639659404755
Starting Epoch Index 29
Evaluating train set
Epoch: 29, Batch Index: 5800- Eval train - q_loss = 0.39020 , q_risk_0.1 = 0.21734 , q_risk_0.5 = 0.52575 , q_risk_0.9 = 0.23267
Evaluating validation set
Epoch: 29, Batch Index: 5800- Eval validation - q_loss = 0.36615 , q_risk_0.1 = 0.18721 , q_risk_0.5 = 0.49772 , q_risk_0.9 = 0.22981
Evaluating test set
Epoch: 29, Batch Index: 5800- Eval test - q_loss = 0.40220 , q_risk_0.1 = 0.22248 , q_risk_0.5 = 0.54862 , q_risk_0.9 = 0.24761
Epoch: 29, Batch Index: 5800 - Train Loss = 0.39212010741233827
Epoch: 29, Batch Index: 5820 - Train Loss = 0.39072294294834137
Epoch: 29, Batch Index: 5840 - Train Loss = 0.39052855253219604
Epoch: 29, Batch Index: 5860 - Train Loss = 0.39218976140022277
Epoch: 29, Batch Index: 5880 - Train Loss = 0.3931941443681717
Epoch: 29, Batch Index: 5900 - Train Loss = 0.393218988776207
Epoch: 29, Batch Index: 5920 - Train Loss = 0.39163510739803314
Epoch: 29, Batch Index: 5940 - Train Loss = 0.3915703827142715
Epoch: 29, Batch Index: 5960 - Train Loss = 0.3931459194421768
Epoch: 29, Batch Index: 5980 - Train Loss = 0.3931496340036392
Starting Epoch Index 30
Evaluating train set
Epoch: 30, Batch Index: 6000- Eval train - q_loss = 0.39057 , q_risk_0.1 = 0.21825 , q_risk_0.5 = 0.52727 , q_risk_0.9 = 0.23261
Evaluating validation set
Epoch: 30, Batch Index: 6000- Eval validation - q_loss = 0.36738 , q_risk_0.1 = 0.18919 , q_risk_0.5 = 0.49924 , q_risk_0.9 = 0.22976
Evaluating test set
Epoch: 30, Batch Index: 6000- Eval test - q_loss = 0.40191 , q_risk_0.1 = 0.22286 , q_risk_0.5 = 0.54679 , q_risk_0.9 = 0.24536
Epoch: 30, Batch Index: 6000 - Train Loss = 0.3902744472026825
Epoch: 30, Batch Index: 6020 - Train Loss = 0.3907164472341538
Epoch: 30, Batch Index: 6040 - Train Loss = 0.39019503772258757
Epoch: 30, Batch Index: 6060 - Train Loss = 0.3909304445981979
Epoch: 30, Batch Index: 6080 - Train Loss = 0.3915932935476303
Epoch: 30, Batch Index: 6100 - Train Loss = 0.3912838155031204
Epoch: 30, Batch Index: 6120 - Train Loss = 0.39170918226242063
Epoch: 30, Batch Index: 6140 - Train Loss = 0.3924876689910889
Epoch: 30, Batch Index: 6160 - Train Loss = 0.39197428166866305
Epoch: 30, Batch Index: 6180 - Train Loss = 0.3910445886850357
Starting Epoch Index 31
Evaluating train set
Epoch: 31, Batch Index: 6200- Eval train - q_loss = 0.38975 , q_risk_0.1 = 0.21851 , q_risk_0.5 = 0.52767 , q_risk_0.9 = 0.23239
Evaluating validation set
Epoch: 31, Batch Index: 6200- Eval validation - q_loss = 0.36598 , q_risk_0.1 = 0.18756 , q_risk_0.5 = 0.49667 , q_risk_0.9 = 0.22891
Evaluating test set
Epoch: 31, Batch Index: 6200- Eval test - q_loss = 0.40154 , q_risk_0.1 = 0.22225 , q_risk_0.5 = 0.54562 , q_risk_0.9 = 0.24451
Epoch: 31, Batch Index: 6200 - Train Loss = 0.3908955878019333
Epoch: 31, Batch Index: 6220 - Train Loss = 0.3918736004829407
Epoch: 31, Batch Index: 6240 - Train Loss = 0.39150700986385345
Epoch: 31, Batch Index: 6260 - Train Loss = 0.39203780233860014
Epoch: 31, Batch Index: 6280 - Train Loss = 0.3901748996973038
Epoch: 31, Batch Index: 6300 - Train Loss = 0.38915141344070436
Epoch: 31, Batch Index: 6320 - Train Loss = 0.39070659518241885
Epoch: 31, Batch Index: 6340 - Train Loss = 0.3905073881149292
Epoch: 31, Batch Index: 6360 - Train Loss = 0.3902280455827713
Epoch: 31, Batch Index: 6380 - Train Loss = 0.3916871452331543
Starting Epoch Index 32
Evaluating train set
Epoch: 32, Batch Index: 6400- Eval train - q_loss = 0.38995 , q_risk_0.1 = 0.21762 , q_risk_0.5 = 0.52858 , q_risk_0.9 = 0.23154
Evaluating validation set
Epoch: 32, Batch Index: 6400- Eval validation - q_loss = 0.36668 , q_risk_0.1 = 0.18702 , q_risk_0.5 = 0.49939 , q_risk_0.9 = 0.22871
Evaluating test set
Epoch: 32, Batch Index: 6400- Eval test - q_loss = 0.40167 , q_risk_0.1 = 0.22138 , q_risk_0.5 = 0.54762 , q_risk_0.9 = 0.24413
Epoch: 32, Batch Index: 6400 - Train Loss = 0.39202110826969144
Epoch: 32, Batch Index: 6420 - Train Loss = 0.39096222519874574
Epoch: 32, Batch Index: 6440 - Train Loss = 0.39030987441539766
Epoch: 32, Batch Index: 6460 - Train Loss = 0.3898254519701004
Epoch: 32, Batch Index: 6480 - Train Loss = 0.39056360721588135
Epoch: 32, Batch Index: 6500 - Train Loss = 0.39097073435783386
Epoch: 32, Batch Index: 6520 - Train Loss = 0.3911157739162445
Epoch: 32, Batch Index: 6540 - Train Loss = 0.391190242767334
Epoch: 32, Batch Index: 6560 - Train Loss = 0.39081517279148104
Epoch: 32, Batch Index: 6580 - Train Loss = 0.38984852373600004
Starting Epoch Index 33
Evaluating train set
Epoch: 33, Batch Index: 6600- Eval train - q_loss = 0.38943 , q_risk_0.1 = 0.21677 , q_risk_0.5 = 0.52403 , q_risk_0.9 = 0.23132
Evaluating validation set
Epoch: 33, Batch Index: 6600- Eval validation - q_loss = 0.36607 , q_risk_0.1 = 0.18704 , q_risk_0.5 = 0.49742 , q_risk_0.9 = 0.22981
Evaluating test set
Epoch: 33, Batch Index: 6600- Eval test - q_loss = 0.40122 , q_risk_0.1 = 0.22210 , q_risk_0.5 = 0.54654 , q_risk_0.9 = 0.24553
Epoch: 33, Batch Index: 6600 - Train Loss = 0.39000167965888977
Epoch: 33, Batch Index: 6620 - Train Loss = 0.38943089842796325
Epoch: 33, Batch Index: 6640 - Train Loss = 0.39088996946811677
Epoch: 33, Batch Index: 6660 - Train Loss = 0.3900245302915573
Epoch: 33, Batch Index: 6680 - Train Loss = 0.3895224344730377
Epoch: 33, Batch Index: 6700 - Train Loss = 0.38981278002262115
Epoch: 33, Batch Index: 6720 - Train Loss = 0.38963438451290133
Epoch: 33, Batch Index: 6740 - Train Loss = 0.39057372629642484
Epoch: 33, Batch Index: 6760 - Train Loss = 0.3902643966674805
Epoch: 33, Batch Index: 6780 - Train Loss = 0.3898572677373886
Starting Epoch Index 34
Evaluating train set
Epoch: 34, Batch Index: 6800- Eval train - q_loss = 0.39050 , q_risk_0.1 = 0.21721 , q_risk_0.5 = 0.52811 , q_risk_0.9 = 0.23194
Evaluating validation set
Epoch: 34, Batch Index: 6800- Eval validation - q_loss = 0.36954 , q_risk_0.1 = 0.18786 , q_risk_0.5 = 0.50398 , q_risk_0.9 = 0.23089
Evaluating test set
Epoch: 34, Batch Index: 6800- Eval test - q_loss = 0.40233 , q_risk_0.1 = 0.22209 , q_risk_0.5 = 0.54882 , q_risk_0.9 = 0.24447
Epoch: 34, Batch Index: 6800 - Train Loss = 0.3901339966058731
Epoch: 34, Batch Index: 6820 - Train Loss = 0.390858815908432
Epoch: 34, Batch Index: 6840 - Train Loss = 0.3913135600090027
Epoch: 34, Batch Index: 6860 - Train Loss = 0.3918037086725235
Epoch: 34, Batch Index: 6880 - Train Loss = 0.3909101969003677
Epoch: 34, Batch Index: 6900 - Train Loss = 0.3903788596391678
Epoch: 34, Batch Index: 6920 - Train Loss = 0.3911781603097916
Epoch: 34, Batch Index: 6940 - Train Loss = 0.3906527698040009
Epoch: 34, Batch Index: 6960 - Train Loss = 0.39001287817955016
Epoch: 34, Batch Index: 6980 - Train Loss = 0.3880264741182327
Starting Epoch Index 35
Evaluating train set
Epoch: 35, Batch Index: 7000- Eval train - q_loss = 0.39028 , q_risk_0.1 = 0.22122 , q_risk_0.5 = 0.52642 , q_risk_0.9 = 0.23083
Evaluating validation set
Epoch: 35, Batch Index: 7000- Eval validation - q_loss = 0.36812 , q_risk_0.1 = 0.19225 , q_risk_0.5 = 0.49813 , q_risk_0.9 = 0.22896
Evaluating test set
Epoch: 35, Batch Index: 7000- Eval test - q_loss = 0.40325 , q_risk_0.1 = 0.22655 , q_risk_0.5 = 0.54788 , q_risk_0.9 = 0.24391
Epoch: 35, Batch Index: 7000 - Train Loss = 0.3893417567014694
Epoch: 35, Batch Index: 7020 - Train Loss = 0.39094632387161254
Epoch: 35, Batch Index: 7040 - Train Loss = 0.3901081711053848
Epoch: 35, Batch Index: 7060 - Train Loss = 0.3909002935886383
Epoch: 35, Batch Index: 7080 - Train Loss = 0.38972910821437834
Epoch: 35, Batch Index: 7100 - Train Loss = 0.39056070685386657
Epoch: 35, Batch Index: 7120 - Train Loss = 0.3917739289999008
Epoch: 35, Batch Index: 7140 - Train Loss = 0.39201636493206027
Epoch: 35, Batch Index: 7160 - Train Loss = 0.39356399834156036
Epoch: 35, Batch Index: 7180 - Train Loss = 0.3922375839948654
Starting Epoch Index 36
Evaluating train set
Epoch: 36, Batch Index: 7200- Eval train - q_loss = 0.38957 , q_risk_0.1 = 0.21744 , q_risk_0.5 = 0.52563 , q_risk_0.9 = 0.23092
Evaluating validation set
Epoch: 36, Batch Index: 7200- Eval validation - q_loss = 0.36618 , q_risk_0.1 = 0.18797 , q_risk_0.5 = 0.49785 , q_risk_0.9 = 0.22884
Evaluating test set
Epoch: 36, Batch Index: 7200- Eval test - q_loss = 0.40127 , q_risk_0.1 = 0.22190 , q_risk_0.5 = 0.54540 , q_risk_0.9 = 0.24297
Performing early stopping...!
Explore Model Outputs¶
After training the model, we can use it and its outputs for a better understanding of its performance, and for trying to explain its estimations. That is what will be demonstrated in this tutorial, using the module tft_torch.tft_vis. We will rely on the dataset we produced on the dataset creation tutorial and on the model we trained in the model training tutorial.
[29]:
import tft_torch.visualize as tft_vis
Apply the model¶
For collecting the outputs of the model, we’ll first run inference on the validation subset. Here we use the serial data loader assigned above:
[30]:
model.eval() # switch to evaluation mode
output_aggregator = dict() # will be used for aggregating the outputs across batches
with torch.no_grad():
# go over the batches of the serial data loader
for batch in tqdm(validation_serial_loader):
# process each batch
if is_cuda:
for k in list(batch.keys()):
batch[k] = batch[k].to(device)
batch_outputs = model(batch)
# accumulate outputs, as well as labels
for output_key,output_tensor in batch_outputs.items():
output_aggregator.setdefault(output_key,[]).append(output_tensor.cpu().numpy())
output_aggregator.setdefault('target',[]).append(batch['target'].cpu().numpy())
100%|██████████| 30/30 [00:10<00:00, 2.74it/s]
and then stack the outpus from all the batches:
[31]:
validation_outputs = dict()
for k in list(output_aggregator.keys()):
validation_outputs[k] = np.concatenate(output_aggregator[k],axis=0)
Let’s say the subset we’re working with includes \(N\) observations, and each observation consists of:
a historical time-series that includes \(m_{historical}\) temporal variables, spanning \(T_{past}\) past time-steps.
a futuristic time-series including \(m_{future}\) temporal variables, spanning \(T_{fut}\) futuristic time-steps.
a set of \(m_{static}\) static variables.
In addition, let’s assume that the model is configured to estimate \(d_q\) different quantiles.
In such case the outputs of the model will be as follows:
predicted_quantiles- the model quantile estimates for each temporal future step, shaped as \([N \times T_{fut} \times d_q]\).static_weights- the selection weights associated with the static variables for each observation, shaped as \([N \times m_{static}]\).historical_selection_weights- the selection weights associated with the historical temporal variables, for each observation, and past time-step, shaped as \([N \times T_{past} \times m_{historical}]\).future_selection_weights- the selection weights associated with the future temporal variables, for each observation, and future time-step, shaped as \([N \times T_{fut} \times m_{future}]\).attention_scores- the attention score each future time-step associates which each other time-step, for each observation, shaped as \([N \times T_{fut} \times (T_{past} + T_{fut})]\).
Some of the illustrations below will refer to a single observation (sample-level), and some will perform aggregation of the outputs for the entire subset data. For that matter, we’ll arbitrarily set an index indicating the sample/record that will be used for the demonstration of the sample-level illustrations:
[32]:
chosen_idx = 42421
Target Signal Trajectory¶
On this section we’ll extract the historical sequence associated with the target variable, for the specific observation chosen, together with the futuristic label (the future target), and the predicted quantiles output by the model.
[33]:
# the name of the target signal
target_signal = 'log_sales'
# its relative index among the set of historical numeric input variables
target_var_index = feature_map['historical_ts_numeric'].index(target_signal)
# the quantiles estimated by the trained model
model_quantiles = configuration['model']['output_quantiles']
The trajectory can be viewed in two different scales: Our first view will refer to the normalized scale. Recall that before feeding the data to the model, all of our input variables were scaled or encoded. because the target signal was scaled as well, the outputs of the model are also designated to estimate the target signal according to this “new” normalized scale.
In the follwing chart we can see: - on the left: the historical values of the target variable. - dashed line separating past and future. - on the right: (solid) future target variable - what the model aims to predict - on the right: (dashed) dashed lines associated with the predicted quantiles (see legend) - on the right: a colored sleeve between and the lower and upper quantiles; can be seen as the uncertainty sleeve for each horizon.
[51]:
tft_vis.display_target_trajectory(signal_history=data['data_sets']['validation']['historical_ts_numeric'][...,target_var_index],
signal_future=validation_outputs['target'],
model_preds=validation_outputs['predicted_quantiles'],
observation_index=chosen_idx,
model_quantiles=model_quantiles,
unit='Days')
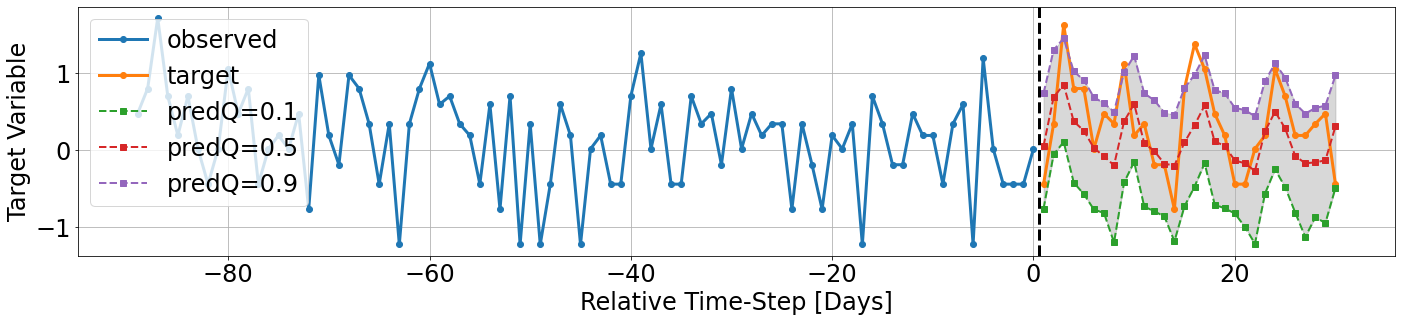
However, in some cases we would like to observe the actual scale of the target variable. For that matter, the method we’re using, tft_vis.display_target_trajectory() optionally accepts also the input argument transformation , which can be used for scaling back the target variable to its original scale.
In our use case, the target variable went through a log-transform (\(log_{10}(1+x)\)), and then scaled using the scaler we saved along with the data. We use this to formulate the inverse scaling, and send this transformation to the visualization utility.
[52]:
def scale_back(scaler_obj,signal):
inv_trans = scaler_obj.inverse_transform(copy.deepcopy(signal))
return np.power(10,inv_trans) - 1
transform_back = partial(scale_back,data['scalers']['numeric'][target_signal])
[53]:
tft_vis.display_target_trajectory(signal_history=data['data_sets']['validation']['historical_ts_numeric'][...,target_var_index],
signal_future=validation_outputs['target'],
model_preds=validation_outputs['predicted_quantiles'],
observation_index=chosen_idx,
model_quantiles=model_quantiles,
unit='Days',
transformation=transform_back)
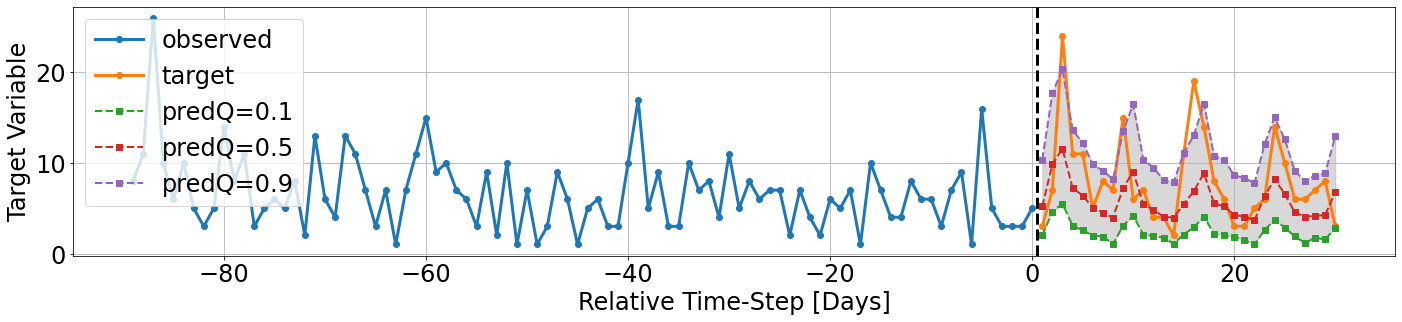
Selection Weights¶
The temporal fusion transformer model has an interntal mechanism for variable selection. Each input channel has a separate dedicated mechanism - historical temporal data, static descriptors data, known future inputs data. In the following section we’ll describe them visually.
Although the input to the model required us to split between the categorical variables and the numeric variables for each input channel, after the inputs are transformed upon feeding them to the model, the entire set of variables composing a single input channel (historical_ts / future_ts / static) are treated as one block, and the variable selection mechanism acts on them without any distinction.
Note: in the suggested implementation, the numeric inputs are stacked first, before combining the categorical inputs (on each input channel separately). Hence, we conclude the complete set of input variables for each input channel as follows:
[37]:
static_feats = feature_map['static_feats_numeric'] + feature_map['static_feats_categorical']
historical_feats = feature_map['historical_ts_numeric'] + feature_map['historical_ts_categorical']
future_feats = feature_map['future_ts_numeric'] + feature_map['future_ts_categorical']
The description of selection weights can be done either on a data subset level, or on a sample-level. For performing data-set level description, we’ll have to perform some-kind of reduction/aggregation. Hence, we use a configurable list of precentiles, for describing the distribution of selection weights for each variable on each input channel:
[38]:
# the precentiles to compute for describing the distribution of the weights
weights_prctile = [10,50,90]
On the following we use the functionality implemented under tft_torch.visualize, for performing the aggregation and ordering of the attributes, for each input channel separately. For that matter, we supply a mapping specifying the name of output key associated which each set of attributes:
[39]:
mapping = {
'Static Weights': {'arr_key': 'static_weights', 'feat_names':static_feats},
'Historical Weights': {'arr_key': 'historical_selection_weights', 'feat_names':historical_feats},
'Future Weights': {'arr_key': 'future_selection_weights', 'feat_names':future_feats},
}
tft_vis.display_selection_weights_stats(outputs_dict=validation_outputs,
prctiles=weights_prctile,
mapping=mapping,
sort_by=50)
Static Weights
=========
| 10 | 50 | 90 | |
|---|---|---|---|
| item_class | 0.146418 | 0.215050 | 0.294322 |
| store_nbr | 0.097868 | 0.175210 | 0.300055 |
| item_nbr | 0.113144 | 0.168956 | 0.242336 |
| item_family | 0.064974 | 0.099162 | 0.178956 |
| city | 0.052091 | 0.074115 | 0.111037 |
| store_type | 0.038503 | 0.066235 | 0.112813 |
| state | 0.028883 | 0.063422 | 0.190131 |
| perishable | 0.015476 | 0.030384 | 0.070544 |
| store_cluster | 0.016169 | 0.020616 | 0.029639 |
Historical Weights
=========
| 10 | 50 | 90 | |
|---|---|---|---|
| log_sales | 0.517847 | 0.575107 | 0.607477 |
| day_of_week | 0.161197 | 0.188109 | 0.217286 |
| day_of_month | 0.029436 | 0.049185 | 0.084286 |
| onpromotion | 0.036496 | 0.046337 | 0.068408 |
| month | 0.013957 | 0.028247 | 0.065884 |
| regional_holiday | 0.013225 | 0.020719 | 0.032937 |
| local_holiday | 0.013515 | 0.017147 | 0.020924 |
| oil_price | 0.010190 | 0.016742 | 0.027128 |
| transactions | 0.011805 | 0.015978 | 0.020759 |
| open | 0.011150 | 0.013105 | 0.015752 |
| national_holiday | 0.007565 | 0.010140 | 0.014467 |
Future Weights
=========
| 10 | 50 | 90 | |
|---|---|---|---|
| day_of_week | 0.221024 | 0.331123 | 0.443231 |
| local_holiday | 0.131050 | 0.189638 | 0.284440 |
| day_of_month | 0.055802 | 0.103773 | 0.213172 |
| onpromotion | 0.063258 | 0.087982 | 0.151555 |
| month | 0.045902 | 0.083580 | 0.122220 |
| national_holiday | 0.035846 | 0.074236 | 0.151380 |
| regional_holiday | 0.022075 | 0.051017 | 0.119778 |
| open | 0.008381 | 0.010621 | 0.014565 |
The tables above display the specified percentiles of the weights distribution for each feature, on each input channel. The color of each cell is highlighted according to the corresponding value (brighter color implies higher value). In addition, every table is sorted (in descending order) according to configured percentile. Note that for the temporal inputs (historical_ts, future_ts), the time-series of weights gets “flattened”, so that we can aggregate along time-steps and samples likewise. Generally, the selection weights for the temporal data, are generated for each time-step separately. Here, we look at all the time-steps altogether, but this can be another aspect to examine.
Some interesting findings that are easily seen using these tables:
For the static weights, the attributes that seem to have the highest weights (thus considered more important), are the ones associated with the identity of the instance - store_nbr , item_class , item_nbr .
The most important variable, in terms of selection weight, among the historical features, is the variable we aim at predicting into the future - log_sales - which makes sense, of course.
Among the known (futuristic) inputs, we see that the knowledge about the next weekdays and the upcoming promotions is of high importance to the model.
As noted earlier, we can examine the selection weights from the point of view of an invdividual sample. Using the functionality implemented on tft_torch.visualize we call display_sample_wise_selection_stats() function, each time for another input channel, specying the observation index for which we want to observe the selection weights distribution.
For each of the input channel we get an ordered barplot of the selection weights. Note that for the selection weights of the temporal attributes, there’s a step of flattening and averaging. For the barplot we also allow specifying the
top_nargument, for keeping only thetop_nranked attributes on this plot. Note that the selection weights on the barplot, for the static variables (which do not require flattening and aggregation) sum up to 1.0 (unless truncated usingtop_n).For the selection weights of the temporal input channel, the same function will also provide some kind of “spectrogram” indicating the distribution of selection weights along time. This visualization can be configured to rank the attributes separately on each time-step, by setting
rank_stepwise=True.
[47]:
# static attributes
tft_vis.display_sample_wise_selection_stats(weights_arr=validation_outputs['static_weights'],
observation_index=chosen_idx,
feature_names=static_feats,
top_n=20,
title='Static Features')
# historical temporal attributes
tft_vis.display_sample_wise_selection_stats(weights_arr=validation_outputs['historical_selection_weights'],
observation_index=chosen_idx,
feature_names=historical_feats,
top_n=20,
title='Historical Features',
rank_stepwise=True)
# futuristic (known) temporal attributes
tft_vis.display_sample_wise_selection_stats(weights_arr=validation_outputs['future_selection_weights'],
observation_index=chosen_idx,
feature_names=future_feats,
top_n=20,
title='Future Features',
historical=False,
rank_stepwise=False)
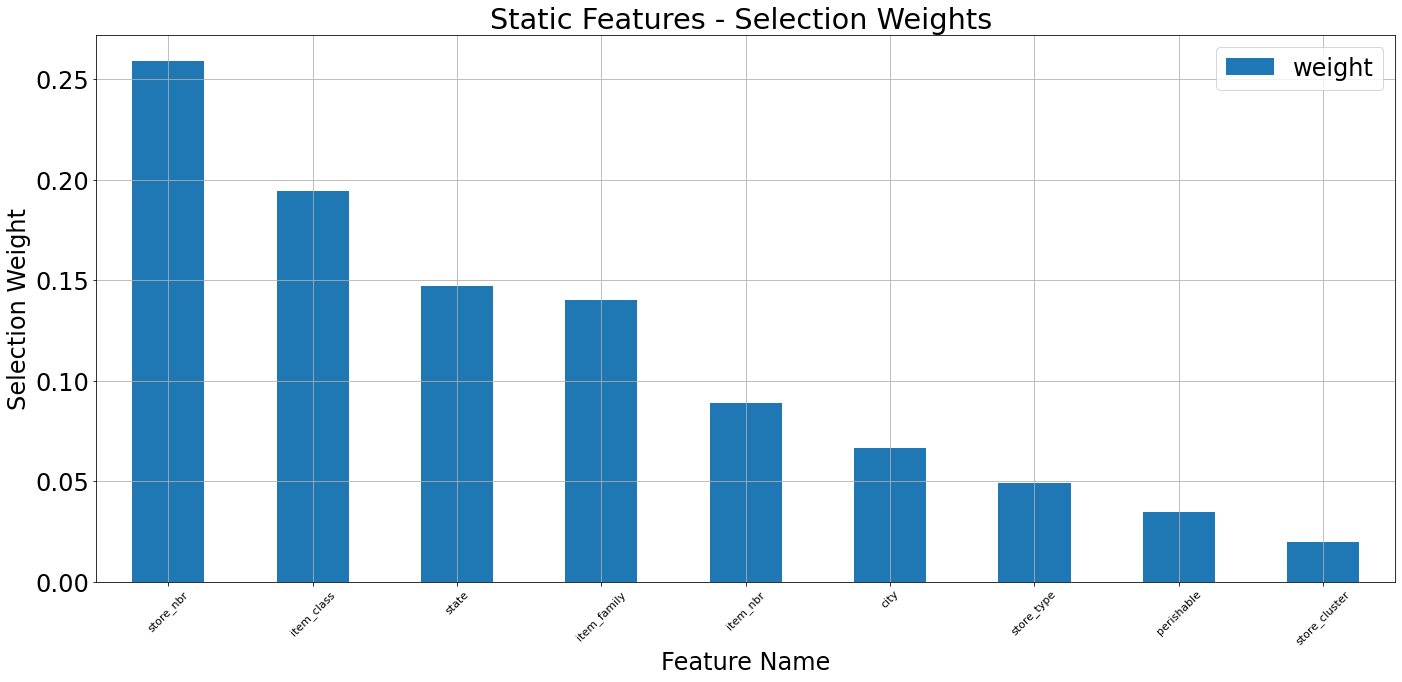
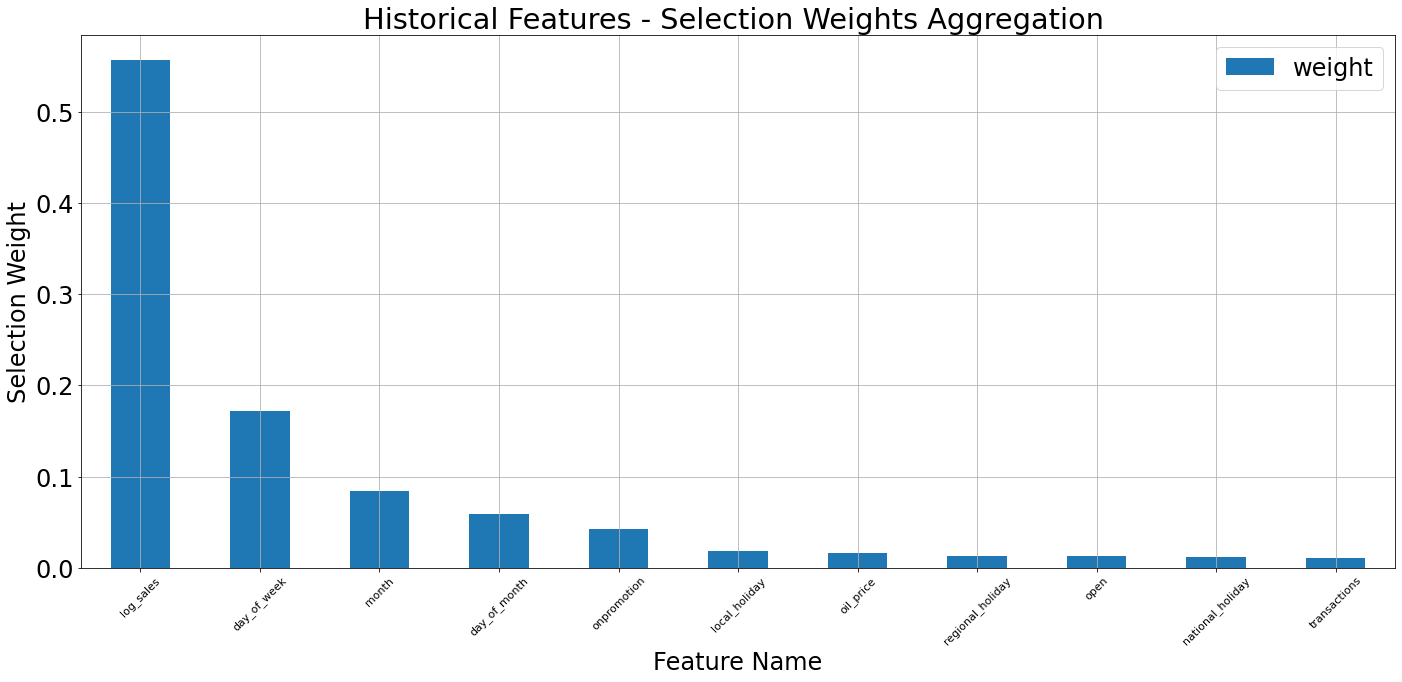
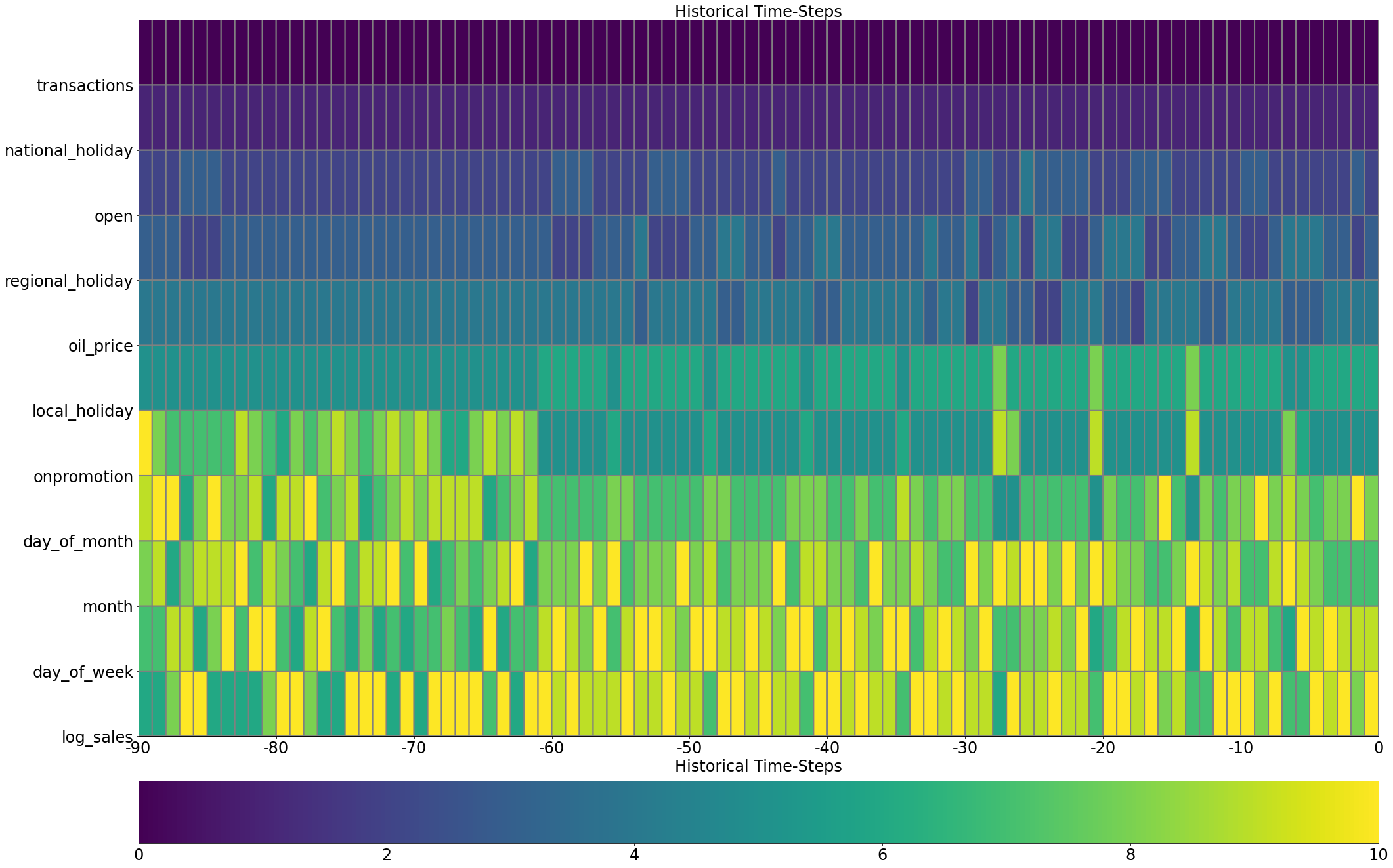
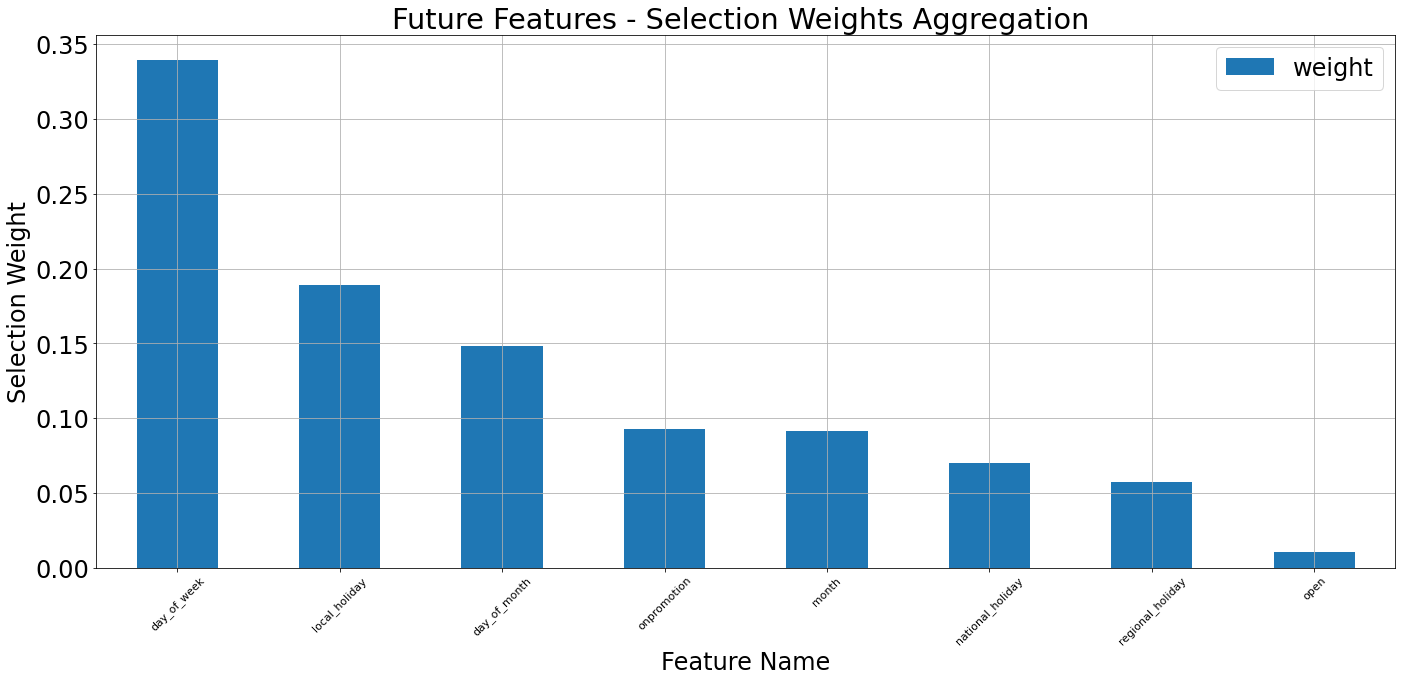
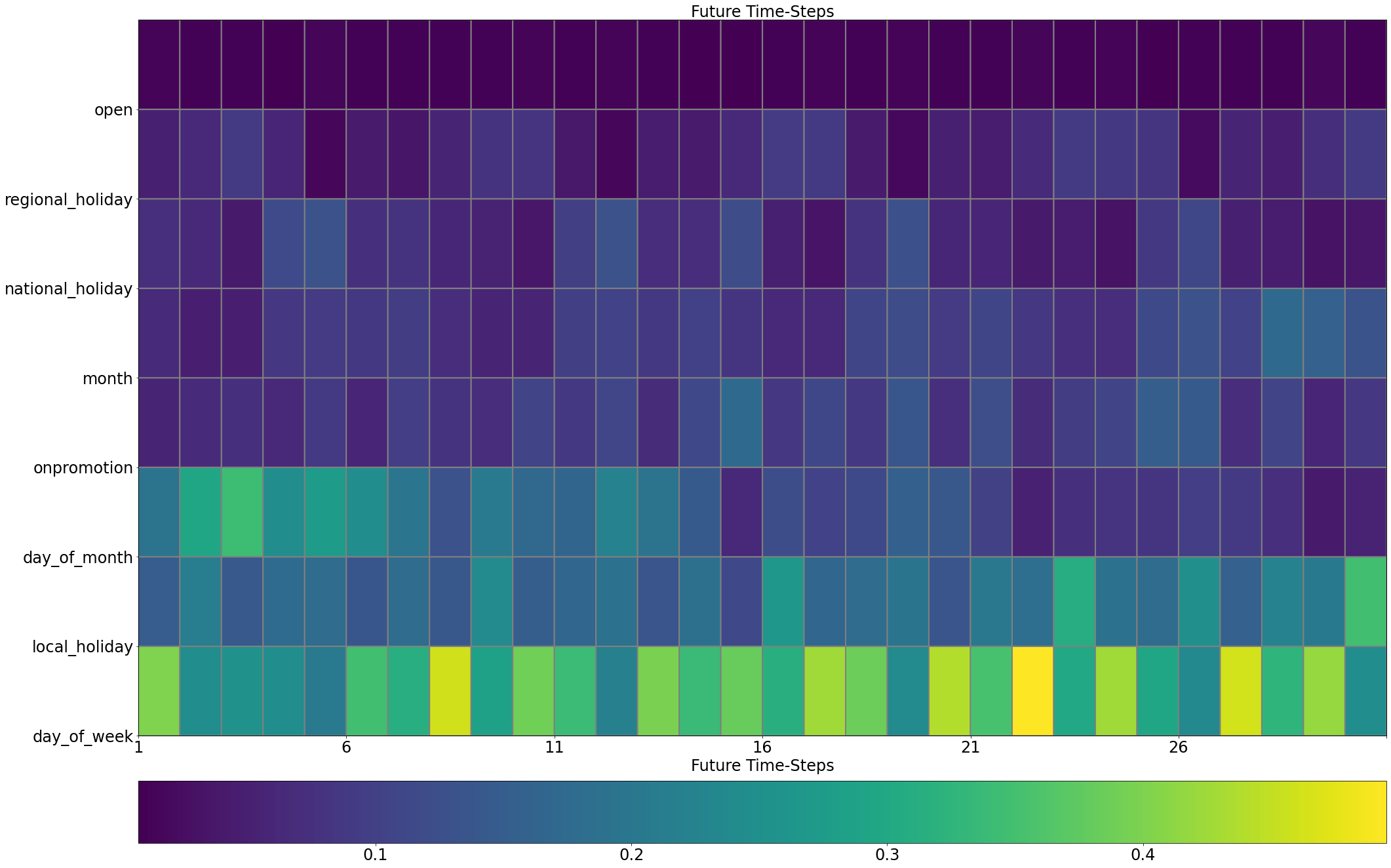
Looking at the barplots above, we can see that although in some cases the ordering of selection weights observed for the individual sample does go hand-in-hand with the ordering observed in the aggregative form (on the dataset level), this might not always be the case. Having the ability to observe selection weights on a single sample level enables us to investigate specific samples and understand which variables of this specific sample affected the model the most, and led to un/successful prediction.
Now, to the additional visualization: as explained above, the distribution of selection weights is different for each time-step. The image-like visualization is used to describe this distribution along time; higher selection weights are depicted by a brighter color. When rank_stepwise is set to False, the visualization is using a uniform scale of selection weights along the entire time axis. Therefore, on time-steps where the distribution of selection weights has higher entropy (less
concentrated with a narrow set of few features), the selected input variables seem (according to chart) “less important”. In order to overcome this, one can set rank_stepwise to True, and the chart will display the same information, but the cells will be colored according to the order of the features (or according to their resepctive selection weight, to be precise) on each time step separately.
Attention Scores¶
The temporal fusion transformer model has an internal attention mechanism for weighting the information coming from the sequential data (whether it is the historical sequence or the future sequential data). Part of the model outputs, for each observation, are the attention scores of the model. We can use these scores to try and infer which preceding time-steps affected the output of the model the most. Recall that due to masking, each Future horizon can “assign” attention only to steps that came before. On this part, we examine the scores both globally (for the entire validation set) and individually (on a single-sample level).
As in the case of aggregating the selection weights, for supply a quantitative description of the scores distribution we use percentiles.
One step ahead¶
The attention scores are horizon-specific, i.e. every future horizon maintains a different set of attention scores for the corresponding observable time-steps. First, we’ll examine the attention scores for a one-day horizon (t+1) into the future.
[48]:
tft_vis.display_attention_scores(attention_scores=validation_outputs['attention_scores'],
horizons=1,
prctiles=[10,50,90],
unit='Days')
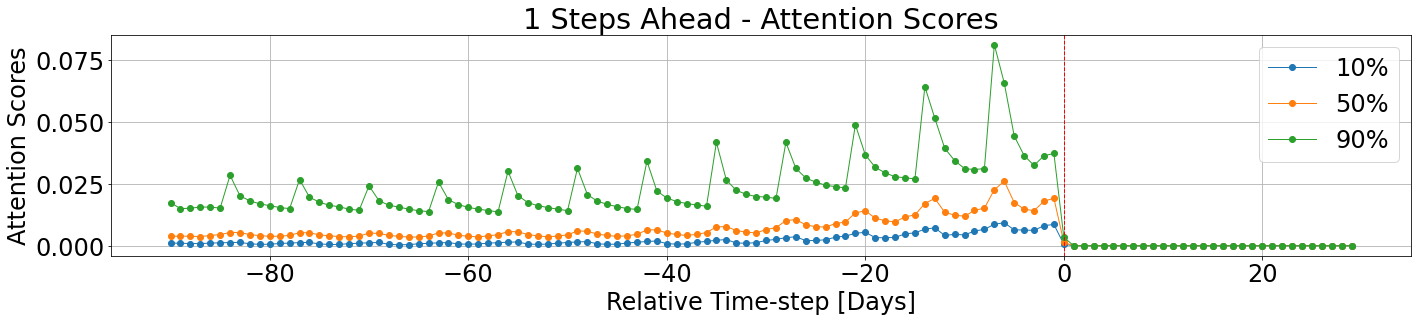
The dashed line stands for the separation between the historical time-steps, and the futuristic time-steps. For each step we compute the relevant percentiles of the attention scores. The attention scores for the further time-steps are zeroed out by design, using the internal masking mechanism within the TFT model. We can see clearly the 7 days cycle among the attention scores, and the general trend according to which the most recent cycles (the ones that are closer to the separation line, are more dominant than previous, gradually forgotten, cycles.
Multihorizon Attention¶
As noted above, each future horizon step has its own set of attention scores. Using the same function we can describe the attention scores distribution for multiple horizons at once.
[49]:
tft_vis.display_attention_scores(attention_scores=validation_outputs['attention_scores'],
horizons=[1,3,5],
prctiles=50,
unit='Days')
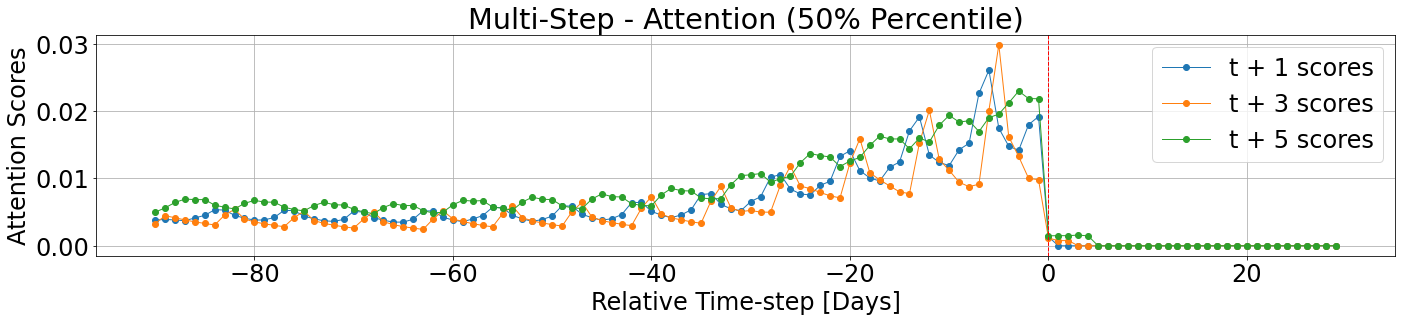
We can see that the attention scores for the historical time-steps have quite similiar characteristics among the different horizons. They all are decaying towards the past, they all have weekly cycles, but, their weekly cycles are offset due to the difference in weekdays.
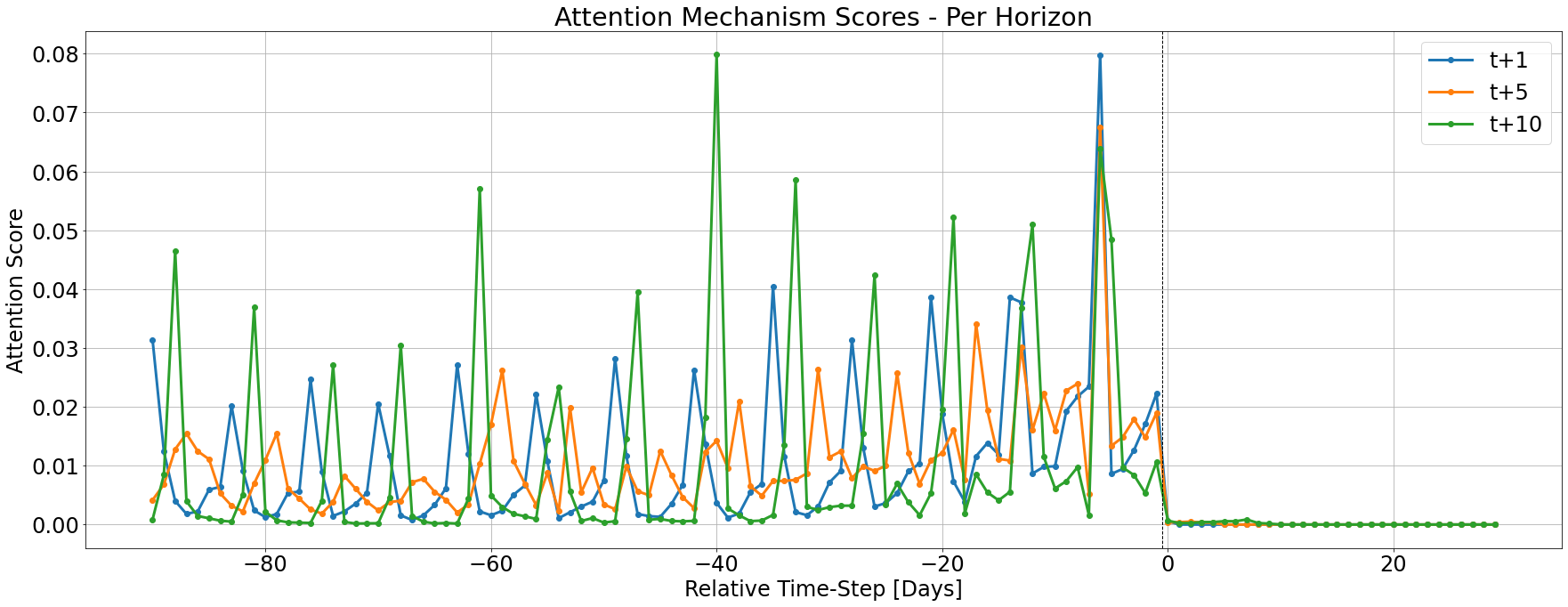
The attention scores can also be explored in the single-sample level using display_sample_wise_attention_scores() function. The following chart presents the scores associated with each output horizon (see legend). When we compare scorings of different horizons, we can see that the attention scores signal is somewhat correlated between two differnet horizon.
[50]:
tft_vis.display_sample_wise_attention_scores(attention_scores=validation_outputs['attention_scores'],
observation_index=chosen_idx,
horizons=[1,5,10],
unit='Days')
And that’s it! Enjoy using tft_torch